

Downtimes can cost organisations between 100K to 300K in losses every hour! That’s huge!
Incident metrics form a good baseline for organisations to understand how, when and why certain incidents happen and how to avoid them. Developing effective incident retrospective encourages organisations to root out system problems.
What is Incident Management
Incident management is an important part of your overall work order management and involves a set of guidelines to be followed when your normal business operations are disrupted due to a certain unplanned incident.
Different incidents can affect businesses in different ways. From downtimes to glitches the consequences can result in late payments, project delays, damage to business reputation and dissatisfied customers.
Having a clear incident management process can help organisations resolve problems faster, cut down costs due to downtime and deliver a better customer experience.
Importance of Incident Management Metrics
Choosing incident management metrics or KPIs (Key Performance Indicators) helps maintenance managers determine whether they are meeting their goals regarding incident management or not. These metrics should also be included in your property maintenance checklist to help you evaluate how successfully your teams are performing.
Some of the most common incident metrics include:
- MTBF – Mean Time Before Failure
- MTTR – Mean Time to Recovery, Repair, Respond, or Resolve
- MTTF – Mean Time to Failure
- MTTA – Mean Time to Acknowledge
A note about MTTR: While it sounds like a single metric, it represents four different things with different meanings. Hence, when setting up this metric, it’s important to know exactly what your teams are measuring in order to be on the same page.
Now that we have defined each of these metrics, let’s dig deeper into what they are, how they are calculated and when they should be used.
What is MTBF, how its calculated and when to use it
MTBF is the mean time before failure. This metric calculates the average time that passes by between repairable failures of an asset. The purpose of this metric is to understand how reliable the equipment is. It also measures for how long it is available for use.
The higher the time between failure, the more reliable the system is.
Calculating MTBF involves taking the data for a certain period for example 6 months, and then dividing the system’s up time over that period by the total number of failures that took place.
MTBF is ideal for systems that are repairable in case of breakdowns. This method is used for businesses where downtime can cause damage such as loss of lives, for example air crafts or high-risk manufacturing equipment.
The information collected to calculate MTBF is also useful for internal teams to make recommendations regarding scheduled maintenance, changing parts and making upgrades.
What is MTTR, how its calculated and when to use it
Mean time to repair
Mean time to repair is the average time it takes to get a system up and running again. This includes the testing time as well. This metric is calculated by counting the total time it has taken to get the system repaired in a given period and then dividing that time by the number of repairs occurred during that period.
This metric is not capable of identifying repairs before the need arises or identify potential issues with the system. Mean time to repair is only used to evaluate the efficiency of the technicians. It helps the staff to keep track of the pending repair work. Ideally, the lower this number the better it is for the organisation.
Mean time to recovery
Mean time to recovery is the time it takes to restore the system back to its original condition. It includes the time for which the system has been out of order plus the time it took to restore it. It is calculated by adding all the downtime the system has experienced in a given period of time divided by the number of incidents that resulted in that downtime.
This metric calculates the speed of your entire system recovery process and helps to compare it with your defined recovery goals as well as mean time to recovery of your competitors.
However, to understand other variables such as the time between failure and alert, effectiveness of the maintenance team or a problem with the diagnostics process, warrant collection of deeper data insights.
Meantime to resolve
This is the average time it takes to resolve a failure from start to finish, including failure identification, diagnostic, repair and taking measures to ensure that it doesn’t happen again.
Essentially, this requires the maintenance teams to go a step further than the simple recovery process.
Think of this as a remedy to restoring your property after an earthquake and then making sure that your property is earthquake proof.
This metric is calculated by adding up the full time to resolve the issues that happened in a given period of time divided by the number of incidents. Also important to note is that this metric is calculated considering the business hours and not the ones spent working overtime.
Also important to mention is that mean time to resolve is calculated for unplanned failures rather than planned maintenance work.
Mean time to respond
What is MTTA, how its calculated and when to use it
What is MTTF, how its calculated and when to use it
Mean time to failure simply measures the average time between one failure to the next. The goal is to make the number as big as possible.
This metric helps to calculate how long a system is expected to last and to schedule preventive maintenance accordingly. It is derived by calculating the total operating time of the products being assessed, divided by the total number of devices.
For example you are testing the smoke alarm batteries in a building. Battery type A lasts 18 hours. Battery type B lasts 20 Hours, Battery type C lasts 22 Hours while Battery type D lasts 24 hours. This makes a total of 84 hours of battery life divided by 4. So MTTF is 21 hours.
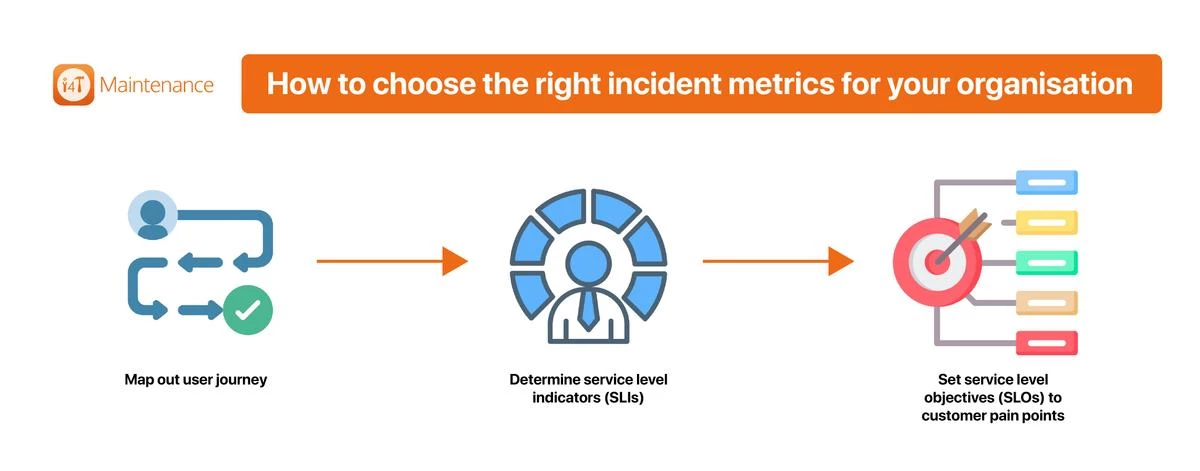
How to choose the right incident metrics for your organisation
Choosing the right incident metrics depends on a number of factors including which industry is in question and what are the needs of the occupants in the facility being managed. The vendors or Field Service Suppliers you hire can help you set up the right incident metrics for the asset in question.
Learn more about Vendor management here.
Here are some steps you can follow to connect incident metrics with customer satisfaction:
- Map out user journey – Doing so helps identify what matters the most to your customers. Try getting into your customers head and ask questions like what slows down the process, what annoys them the most and what equipment or systems they rely the most on. Facility managers can do so by directly talking to the people using these system and even those incharge of fixing them in the past
- Determine service level indicators (SLIs): Understanding what your customers find most valuable helps you understand what data best fits customers needs, and what data should you be capturing.
- Set service level objectives (SLOs) to customer pain points: Ask customers what incidents would be unacceptable for them. These should be analysed in terms of the incident’s impact on customer happiness. This should also be analysed in terms of the error budget and how critical an incident is and how it impacts the system’s reliability.
Creating an incident retrospective
Incident management is all about continuous learning from new findings. Incident metrics can provide valuable insights into a number of factors and future incidents can be avoided to a great extent using them. This is called incident retrospective, where you post mortem the incident and turn experience into knowledge.
As organisations get better about their analysis to incidents, their responses also mature over time
An ideal retrospective should have the following:
- A brief yet complete summary of the incident,
- Its contributing factors using “because” and “why” statements
- The impact it had at the customer level including how it affected their overall satisfaction.
- What follow up actions were taken in response to the incident and ensuring that such incidents are minimised in the future.
- Explain about the activity like you are telling a narrative. This will include all the people involved in identifying the incident and taking action.
- Lay out a timeline of the entire incident including using screenshots and logs.
- Carry out a technical analysis of the incident including errors or bugs and factors dependent upon each other.
- Carry out a process analysis of the way the incident was handled and what went wrong.
- Document communication between key personnel during the incident.
- Ensure the retrospective is created within 48 hours of the incident and store reports in a way that they can be easily accessed should a similar incident take place in the future.
Parting thoughts
Remember, incident management should always be about learning from failures and working together to minimise incidences that may hurt customer satisfaction.
Any post-mortem discussion must not blame individuals, rather, it should be taken as an opportunity to improve processes in the future.


